
Na czym polega regresja do średniej?
Regresja do średniej to powszechne zjawisko statystyczne, które może wprowadzać nas w błąd, gdy obserwujemy świat. Nauczenie się rozpoznawania regresji do średniej może pomóc nam uniknąć błędnej interpretacji danych i dostrzegania wzorców, które nie istnieją.
Definicja i wyjaśnienie
Jeśli twoja ulubiona drużyna zdobyła mistrzostwo w zeszłym roku, czy to oznacza dla jej szans na wygraną w następnym sezonie? To ważne pytanie, często w grę wchodzą pieniądze lub duma (ktoś z Ligi?). O ile wynika to z umiejętności (drużyna jest w dobrej kondycji, czołowy trener itp.), ich zwycięstwo sygnalizuje, że jest większe prawdopodobieństwo, że wygrają w przyszłym roku. Jednak im w większym stopniu jest to zasługa szczęścia (inne drużyny uwikłane w skandal narkotykowy, korzystny remis, dobrze wypadł wybór w losowaniu itp.), tym mniejsze jest prawdopodobieństwo, że wygrają one w przyszłym roku. Dzieje się tak ze względu na statystyczną koncepcję regresji do średniej.
Regresja do średniej – przykłady
Załóżmy, że przeprowadzasz testy i otrzymujesz wyniki (niektóre bardzo dobre, niektóre bardzo złe, a niektóre pośrodku). Ponieważ istnieje pewna szansa związana z ich przeprowadzeniem, po ponownym uruchomieniu testu na te, które były zarówno wyjątkowo dobre, jak i złe, jest bardziej prawdopodobne, że będą one bliższe tym pośrodku. To regresja do średniej.
Przykład zabawy
Wyobraź sobie, że jesteś nauczycielem i dajesz uczniom test prawda/fałsz składający się ze 100 pytań, a twoi uczniowie, choć bystrzy, rzucają monetą, aby wybrać odpowiedź: reszka = prawda; orzeł = fałsz. Można by się spodziewać, że średnia wyników testu wyniesie 50. Oczywiście, dzięki zwykłemu szczęściu, niektórzy uczniowie uzyskają wyniki znacznie powyżej 50, a niektórzy znacznie poniżej 50. Jeśli naiwnie weźmiesz 10% uczniów z najlepszymi wynikami i poddasz ich drugiemu testowi przy użyciu tej samej strategii, oczekuje się, że średni wynik będzie zbliżony do 50. W ten sposób najlepsi uczniowie „cofnęliby się” aż do średniej wszystkich uczniów, którzy wzięli udział w pierwotnym teście.
Jeśli z drugiej strony wyniki testów uczniów nie wiążą się z żadnymi szansami, można się spodziewać, że średnia nie ulegnie regresji, a 10% najlepszych uczniów będzie takich samych w pierwszym i drugim teście. Większość sytuacji znajduje się pomiędzy tymi dwiema skrajnościami i należy spodziewać się regresji do średniej (a to, jak bardzo, zależy od tego, jak duże jest prawdopodobieństwo lub jak zaszumione jest to zjawisko).
Inne przykłady regresji do średniej
W nauce
Jeśli jedno badanie sugeruje, że zdrowotna substancja chemiczna YK7483 przewyższa wszystkie inne metody leczenia filariozy limfatycznej (sprawdzenie tego nie jest dla osób o słabym sercu), nie należy pokładać całej wiary w ten wynik. Podczas drugiego testu YK7483 jest bardziej prawdopodobne, że wynik będzie bliższy średniej. Gdybyś przyjął wartość nominalną i nie uwzględnił faktu, że prawdopodobnie nastąpi regres do średniej, źle ulokowałbyś swoje pieniądze. W jednym z systematycznych badań tego efektu John Ioannidis przeanalizował „49 najbardziej cenionych wyników badań w medycynie w ciągu ostatnich 13 lat” i stwierdził, że 16% badań zostało zakwestionowanych, 16% miało efekty, które były mniejsze w drugim badaniu niż w pierwszym, 24% pozostało w dużej mierze niezakwestionowane, a tylko 44% zostało zreplikowanych. Przypomnijmy, że są to najbardziej cenione wyniki badań, które powinny być bardziej wiarygodne, a nie jakakolwiek stara próbka.
W życiu
Twoja organizacja ma za sobą świetny kwartał, w którym osiągnęła i przekroczyła wszystkie wyznaczone cele. Jeśli przyczyny leżące u podstaw jej wyników nie ulegną zmianie, w kolejnym kwartale poradzi sobie gorzej.
Wszystko to może być nieco przygnębiające, ale weź pod uwagę, że jest też odwrotnie. Nietypowo złe wydarzenia mogą być mniej złe następnym razem! Jeśli ubiegły rok był dla ciebie okropny, powinieneś oczekiwać, że będzie lepiej. Jeśli twoja ulubiona drużyna zajęła ostatnie miejsce w poprzednim sezonie, w tym roku powinno być lepiej!
Źródło: What is regression to the mean?
Zobacz na: Modele mentalne
Zachowania przesądne – gołębie i nagrody
Kryzysowi replikacji w psychologii kończą się wymówki
Dlaczego większość opublikowanych wyników badań jest fałszywa – prof. John Ioannidis
Niedoskonała korelacja i przypadek
W tym momencie możesz zastanawiać się, dlaczego regresja do średniej ma miejsce i jak możemy upewnić się, że jesteśmy tego świadomi, gdy się pojawia.
Aby zrozumieć regresję do średniej, musimy najpierw zrozumieć korelację.
Współczynnik korelacji między dwiema miarami, który waha się od -1 do 1, jest miarą względnej wagi czynników, które dzielą. Na przykład, dwa zjawiska o niewielu wspólnych czynnikach, takie jak konsumpcja wody butelkowanej w porównaniu ze wskaźnikiem samobójstw, powinny mieć współczynnik korelacji bliski 0. Oznacza to, że gdybyśmy spojrzeli na wszystkie kraje na świecie i wykreślili wskaźniki samobójstw w danym roku w stosunku do konsumpcji wody butelkowanej na mieszkańca, wykres nie wykazałby żadnego wzorca.
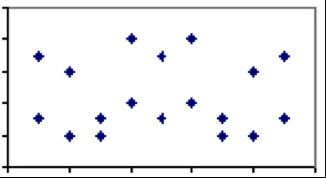
Brak korelacji
Z kolei istnieją też miary, które zależą wyłącznie od tego samego czynnika. Dobrym tego przykładem jest temperatura. Jedyny czynnik determinujący temperaturę – prędkość cząsteczek – jest wspólny dla wszystkich skal, dlatego każdy stopień w skali Celsjusza będzie miał dokładnie jedną odpowiadającą mu wartość w skali Fahrenheita. Dlatego temperatura w stopniach Celsjusza i Fahrenheita będzie miała współczynnik korelacji równy 1, a wykres będzie linią prostą.

Idealna korelacja
Niewiele jest zjawisk w naukach o człowieku, które mają współczynnik korelacji równy 1. Istnieje jednak wiele takich, w których związek jest słaby lub umiarkowany i istnieje pewien czynnik wyjaśniający między dwoma zjawiskami. Rozważmy korelację między wzrostem a wagą, która wylądowałaby gdzieś pomiędzy 0 a 1. Podczas gdy praktycznie każdy trzylatek będzie lżejszy i niższy niż każdy dorosły mężczyzna, nie wszyscy dorośli mężczyźni lub trzylatki o tym samym wzroście będą ważyć tyle samo.

Korelacja od słabej do umiarkowanej
Ta zmienność i odpowiadający jej niższy stopień korelacji sugeruje, że chociaż wzrost jest ogólnie dobrym predyktorem, wyraźnie istnieją czynniki inne niż wzrost. Gdy korelacja dwóch miar jest mniejsza niż idealna, musimy uważać na efekty regresji do średniej.
Daniel Kahneman zaobserwował ogólną zasadę: Ilekroć korelacja między dwoma wynikami jest niedoskonała, wystąpi regresja do średniej.
Na początku może się to wydawać mylące i niezbyt intuicyjne, ale stopień regresji do średniej jest bezpośrednio związany ze stopniem korelacji zmiennych. Efekt ten można zilustrować prostym przykładem.
Załóżmy, że jesteś na przyjęciu i pytasz, dlaczego wysoce inteligentne kobiety mają tendencję do poślubiania mężczyzn, którzy są mniej inteligentni od nich. Większość ludzi, nawet tych z pewnym wykształceniem statystycznym, szybko wyskoczy z różnymi wyjaśnieniami przyczynowymi, od unikania konkurencji po obawy przed samotnością, z którymi borykają się te kobiety. Temat tak kontrowersyjny prawdopodobnie wywoła wielką debatę.
A co by było, gdybyśmy zapytali, dlaczego korelacja między wynikami inteligencji małżonków jest mniej niż idealna? To pytanie nie jest tak interesujące i nie ma co zgadywać – wszyscy wiemy, że to prawda. Paradoks polega na tym, że oba pytania są algebraicznie równoważne. Kahneman wyjaśnia:
„[…] Jeśli korelacja między inteligencją małżonków jest mniejsza niż doskonała (i jeśli mężczyźni i kobiety średnio nie różnią się inteligencją), to matematycznie nieuniknione jest, że wysoce inteligentne kobiety wyjdą za mąż za mężów, którzy są średnio mniej inteligentni niż one (i odwrotnie, oczywiście). Zaobserwowany regres do średniej nie może być bardziej interesujący lub bardziej wytłumaczalny niż niedoskonała korelacja.”
Zakładając, że korelacja jest niedoskonała, szanse na to, że dwóch partnerów reprezentuje 1% najlepszych pod względem jakiejkolwiek cechy, są znacznie mniejsze niż w przypadku jednego partnera reprezentującego 1% najlepszych, a drugiego – 99% najgorszych.
Źródło: Regression Toward the Mean: An Introduction with Examples
Teoria prawdopodobieństwa – dział matematyki zajmujący się analizą zjawisk losowych. Wynik zdarzenia losowego nie może być określony przed jego wystąpieniem, ale może być jednym z kilku możliwych wyników. Rzeczywisty wynik jest uważany za określony przez przypadek.
W teorii prawdopodobieństwa prawo wielkich liczb (law of large numbers – LLN) jest twierdzeniem matematycznym, które mówi, że średnia wyników uzyskanych z dużej liczby niezależnych i identycznych próbek losowych zbiega się do prawdziwej wartości, jeśli taka istnieje. Bardziej formalnie, prawo wielkich liczb mówi, że biorąc pod uwagę próbkę niezależnych i identycznie rozłożonych wartości, średnia z próbki zbiega się do prawdziwej średniej.
Odchylenie standardowe jest miarą tego, jak rozłożone są liczby. Jego symbolem jest σ (grecka litera sigma). Kiedy obliczamy odchylenie standardowe, okazuje się, że ogólnie:

Najnowsze komentarze